
데이터 놀이터
Section 1 - Sprint 1. Data Preprocessing & EDA 본문
1. EDA (Exploratory Data Analysis)
탐색적 데이터 분석, 말 그래도 데이터 분석을 위해 데이터를 탐색하는 과정이다. 마치 우리가 요리를 하기 전에 재료의 특성, 조리법 등을 알아야 하듯이 데이터 분석을 하기 전에 데이터가 어떤 특성, 분포를 갖고 있는지를 알아보는 중요한 단계다. EDA를 수행하기 위해서 pandas 메서드, Feature Engineering, 통계치 및 시각화를 활용한다
(1) pandas 메서드
먼저 통계치를 이용하는 방법에는 다음과 같은 코드가 있다. 모두 pandas의 메서드이다.
df.shape # 행, 열의 수
df.info() # 열 별로 결측치, 데이터타입 등을 종합적으로 파악 가능
df.isnull().sum() # 결측치 수
df.dtypes # 데이터타입
df.duplicated().sum() # 중복값 수이외에도 많은 메서드가 있지만 일단 가장 많이 쓰이는 기본적인 것들만 정리해두려고 한다.
(2) Feature Engineering
주어진 데이터를 가공하여 주목할 만한 특징을 가진 데이터셋을 새로 만들어내는 작업을 말한다. GIGO(Garbage In, Garbage Out) 이라는 말이 있듯이 아무런 의미가 없는 데이터로 분석, 머신러닝 등을 돌리게 되면 정말 의미없는 결과만 도출된다. 때문에 분석 목적에 적합하도록 기존 데이터로부터 유용한 feature를 가진 데이터를 새로 만들어내는 것이다.

feature engineering에서 자주 사용되는 pandas 메서드에는 대표적으로 다음과 같은 것들이 있다.
df.groupby('a')['b'] # a별 b값에 대한 자료 생성
df.columns = ['바꾼 후 열 이름'] # 열 이름 전체 재정의
df.rename({'바꿀 열 이름' : '바꾼 후 열 이름', ...}, axis = 'columns') # 열 이름 부분 재정의
pd.concat # pd.merge, pd.join, pd.append 데이터 프레임 합치기
(3) 통계치 및 시각화
통계치를 확인하는 방법에는 df.describe(), df.describe(exclude = 'number') 메서드가 있다.
시각화는 앞에서 간단히 확인한 통계치를 직관적으로 파악하는데 도움을 주며 데이터 분석의 목적에 따라 다양한 방법으로 이루어진다.
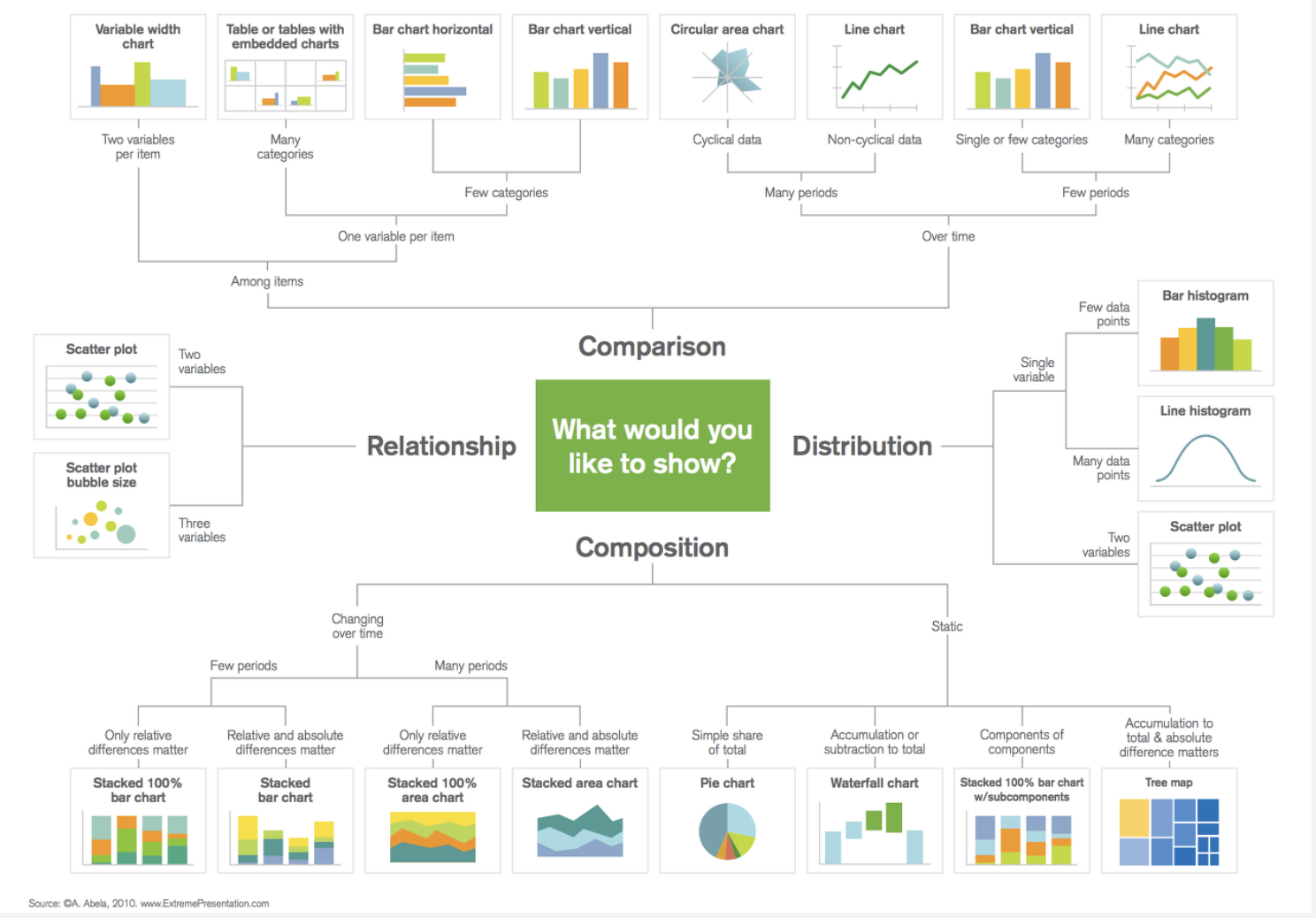
이 그림에서의 시각화 방법 외에 이상치를 확인하거나 여러가지 변수의 분포 차이를 확인하는데 적합한 boxplot, 상관관계를 볼때 적합한 heatmap 등 다양한 시각화 방법들이 있다. 항상 내가 무엇을 목적으로 데이터 분석을 하려고 하는가에 대해 생각해보며 적절한 시각화 방법을 선택한다면 효과적으로 내 생각을 전달할 수 있을 것이다. python에서는 matplotlib과 seaborn 등이 대표적인 시각화 라이브러리다.
2. 데이터 전처리
앞서 EDA를 하는 과정에서 결측치, 중복치, 데이터타입의 문제 등 데이터에 대한 다양한 문제점들을 발견할 수 있을 것이다. 원활한 데이터 분석을 위해서는 이를 해결하는 과정을 거치게 되는데 그 과정이 바로 데이터 전처리이다. 데이터 분석가나 사이언티스트들의 업무 중 많은 시간을 할애하는 부분이 이 분야인 만큼 아주 중요한 과정이라고 할 수 있다.
(1) 데이터 문제 파악
데이터들의 문제점은 크게 품질의 문제, 구조의 문제 두가지로 분류해 볼 수 있다. 먼저 데이터 품질의 문제는 데이터 그 자체의 문제로 결측치, 중복값, 이상값, 부정확한 값 등이 있다. 특히 결측치를 처리하는 것이 까다로운데 같은 내용을 가진 데이터를 참고하여 그 값으로 대체(fillna)하거나 그럴 수 없는 상황이라면 제거(dropna)하는 방안이 있다. 두 번째로 구조의 문제는 테이블의 구조적 문제가 있을 경우이다. 예를 들면 하나의 열에 두 개 이상의 변수가 같이 있는 경우가 있다.
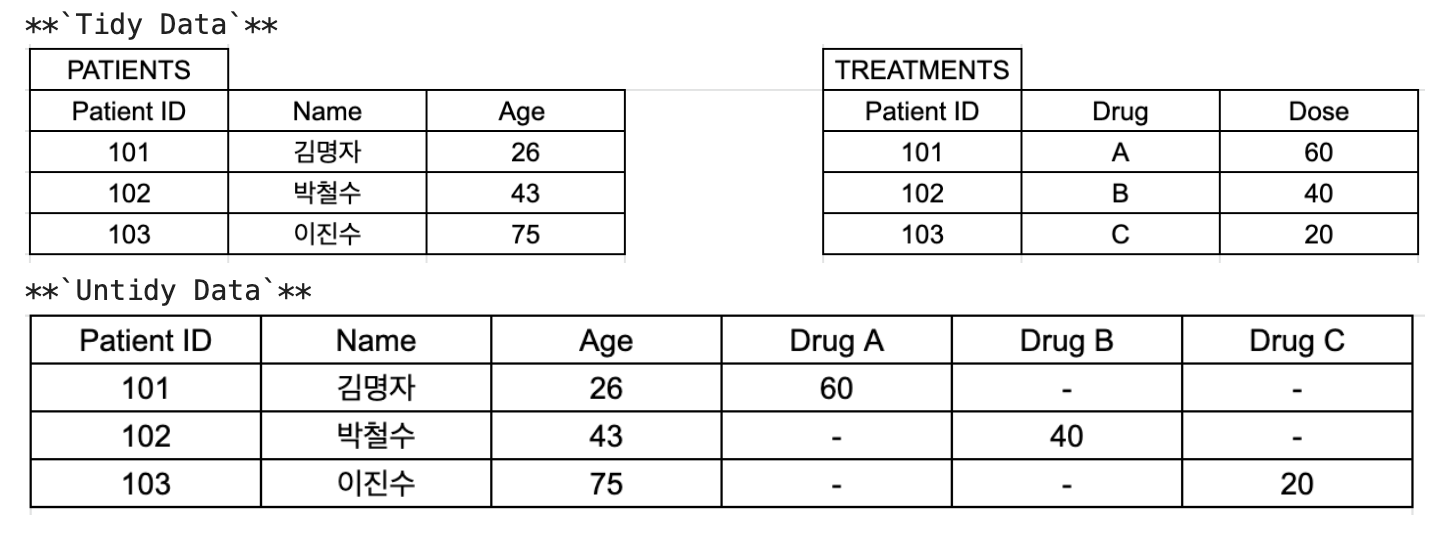
(2) 데이터 정제
데이터가 어떤 종류의 문제를 갖고 있는지 파악했다면 이를 해결하는데 적합한 코드를 적용시켜야 한다.
# 결측치
df.dropna() # 제거
df.fillna() # 대체
# 중복값
df.drop_duplicated() # 제거
# 부정확한 데이터
df.drop() # 열 또는 행 제거
# 데이터 타입 변환
df.astype()
# 데이터 구조 문제 해결
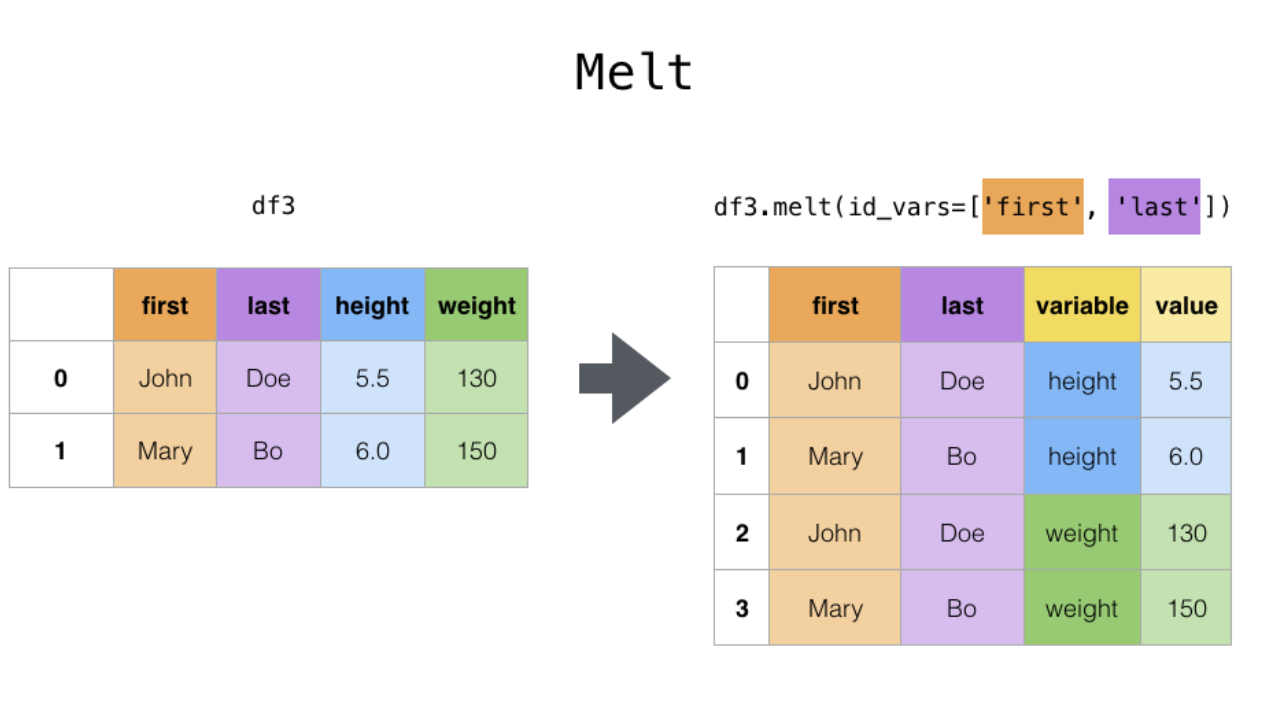
pd.melt(data = ,id_vars = ['바꾸지 않은 열들',...], value_vars = ['바꿀 열들',...],
var_name = ['기준 열 이름'], value_name = ['값 이름'])
# variable - pivot시 기준으로 했을 열(현재 열 이름), value - variable의 값
# pivot table의 반대 역할
melt의 Parameter들이 헷갈리는데 그림을 통해 이해하면 쉽다. (열 -> 변수)
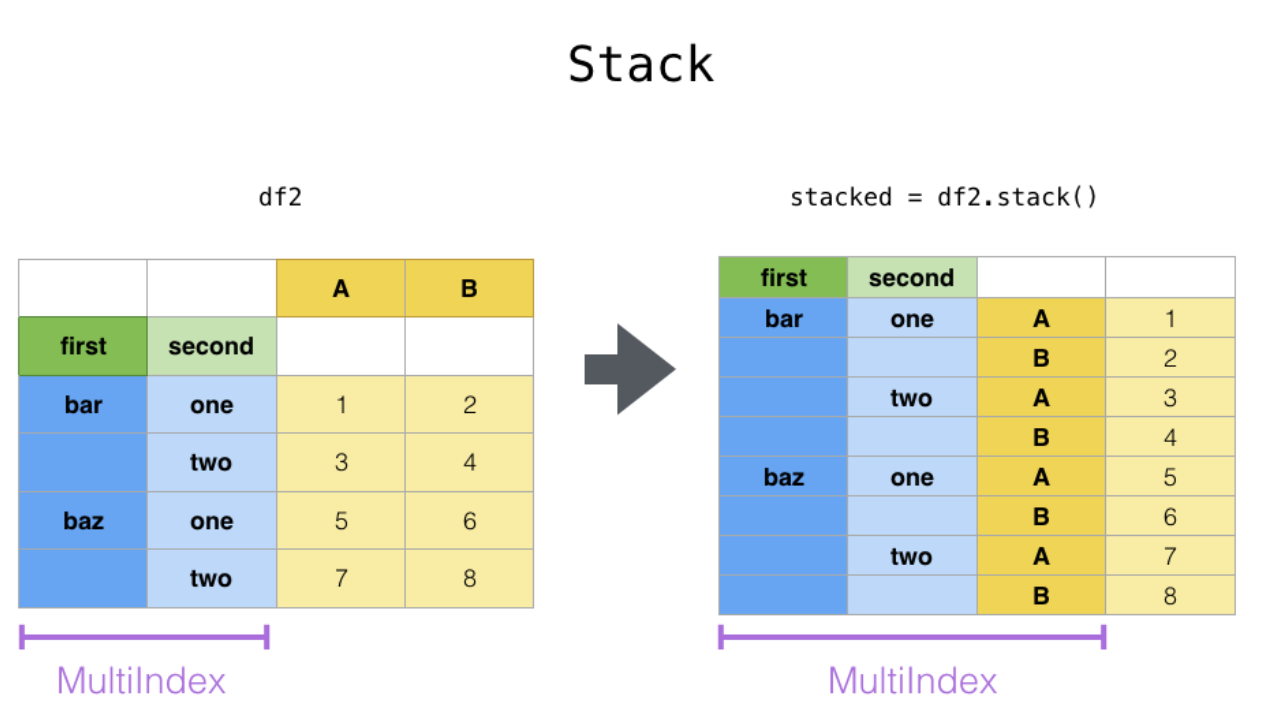
이와 비슷한 개념이 stack인데 같이 알아두면 좋다. (열 -> index)
이 외에도 특정 값을 찾기 위해 조건을 거는 일이 많은데 string에 많이 쓰이는 정규식이 대표적이다. 워낙 복잡한 개념이라 정규식을 설명한 공식 문서를 참고하는 것이 좋다. (https://docs.python.org/ko/3/howto/regex.html, https://docs.python.org/ko/3/library/re.html)
re — Regular expression operations
Source code: Lib/re/ This module provides regular expression matching operations similar to those found in Perl. Both patterns and strings to be searched can be Unicode strings ( str) as well as 8-...
docs.python.org
Regular Expression HOWTO
Author, A.M. Kuchling < amk@amk.ca>,. Abstract: This document is an introductory tutorial to using regular expressions in Python with the re module. It provides a gentler introduction than the corr...
docs.python.org
python 공식 문서 정리본
. ^ $ * + ? { } [ ] \ | ( )
1. 문자 일치
- [] : 문자 클래스 지정, 안에다가 - 를 사용하여 문자의 범위를 나타낼 수도 있음
e.g. 소문자 : [a - z]
클래스 안에서는 \를 제외한 정규표현식은 본래의 역할이 아닌 단순 문자로 취급
클래스 안 ^를 활용하여 여집합 활용 가능
e.g. ^5 : 5를 제외한 모든 문자
- \ :
1) 메타 문자들 앞에 붙여 메타 문자들을 단순 문자 취급 가능
E.g. \\ : \, \[ : [
2) 특수 시퀀스
\d : 모든 십진 숫자와 일치합니다; 이것은 클래스 [0-9]와 동등
\D : 모든 비 숫자 문자와 일치합니다; 이것은 클래스 [^0-9]와 동등
\s : 모든 공백 문자와 일치합니다; 이것은 클래스 [ \t\n\r\f\v] 와 동등
\S : 모든 비 공백 문자와 일치합니다; 이것은 클래스 [^ \t\n\r\f\v] 와 동등
\w : 모든 영숫자(alphanumeric character)와 일치합니다; 이것은 클래스 [a-zA-Z0-9_]와 동등
\W : 모든 비 영숫자와 일치합니다; 이것은 클래스 [^a-zA-Z0-9_]와 동등
3) r’\’
파이썬에서 ‘\’를 나타내고자 할때 \\를 사용해야돼서 정규식에서 온전히 \를 쓰기 어려움
쓰고자 하는 정규시 앞에 r을 붙임으로써 해결 가능
e.g. ‘\\\\section’이라고 쓰는 것이 아니라 r’\\section’
2. 반복하기
* : * 전에 있는 문자를 0번 이상 반복
+ : + 전에 있는 문자를 1번 이상 반복
? : ? 전에 있는 문자를 0번 또는 1번 반복
{m ,n} : 전에 있는 문자를 m이상 n 이하 반복(m 생략시 0, n 생략시 무한대로 해석)
e.g. * : {0,}, + : {1,}, ? : {0, 1}
3. 일치 수행 메서드 ( .str. ~)
.match()
.search()
.findall()
.finditer()
'코드스테이츠 AIB 17' 카테고리의 다른 글
| Section 4 - Sprint 1. 환경과 관계형 데이터 베이스 - 2. SQL, RDB (0) | 2023.03.21 |
|---|---|
| Section 4 - Sprint 1. 환경과 관계형 데이터 베이스 - 1. 개발 환경 (0) | 2023.03.20 |
| Section 2 Review - Machine Learning (0) | 2023.02.14 |
| Section 1 - Sprint 2. Statistics - 1. Bayes Theorem (0) | 2023.01.07 |
| 코드스테이츠 AIB(AI 부트캠프) 17기 합격후기 (0) | 2022.12.29 |

